

Today we are going to take a look at Sketch Engine and learn how to access and use this resource.
What is Sketch Engine?
Before we dive into how to use Sketch Engine, let’s take some time to understand what exactly it is.
Sketch Engine is a language resource that provides linguists access to multiple linguistic tools which analyse data and present it in a clear, easy to comprehend manner.
It is a licensed resource, but we will learn further on in this post how to gain free access as university students.
One of the main characteristics of Sketch Engine is that it works in conjunction with a chosen corpus.
This post is first going to explain how corpora work, so that we can have a better understanding of the type of data Sketch Engine uses.
Following this we are going to discover how to use the various language tools it offers, including concordance, work sketch, word lists, n-grams and the thesaurus.
How to access
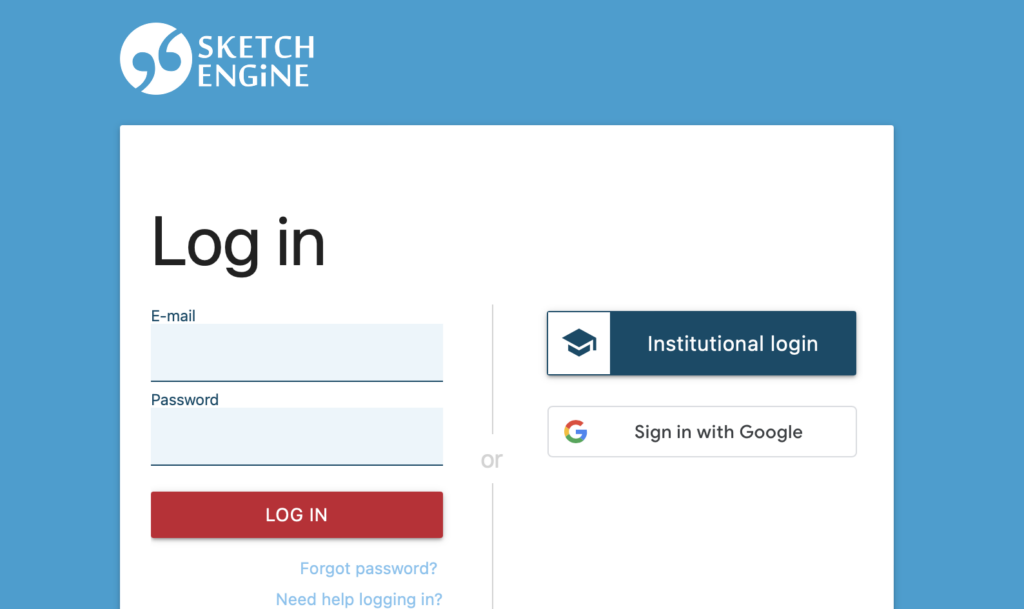
Firstly, let’s look at how we access this resource.
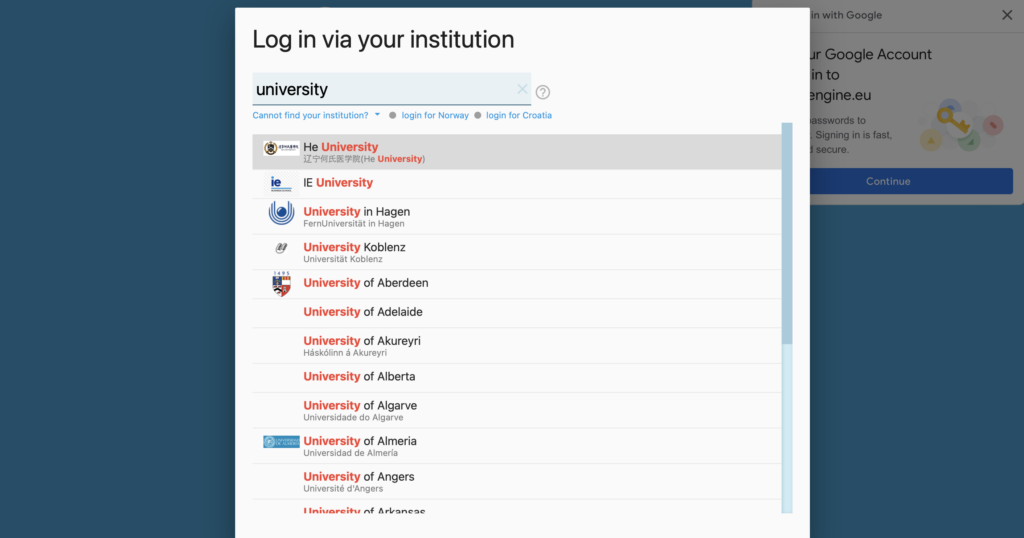
Sketch Engine is a licensed resource which ordinarily requires a paid license to access. Luckily for university students, we are able to avail of the ‘institutional login’ option.
Simply enter your institutions name and use your university log in credentials to gain access.
Identifying the tools
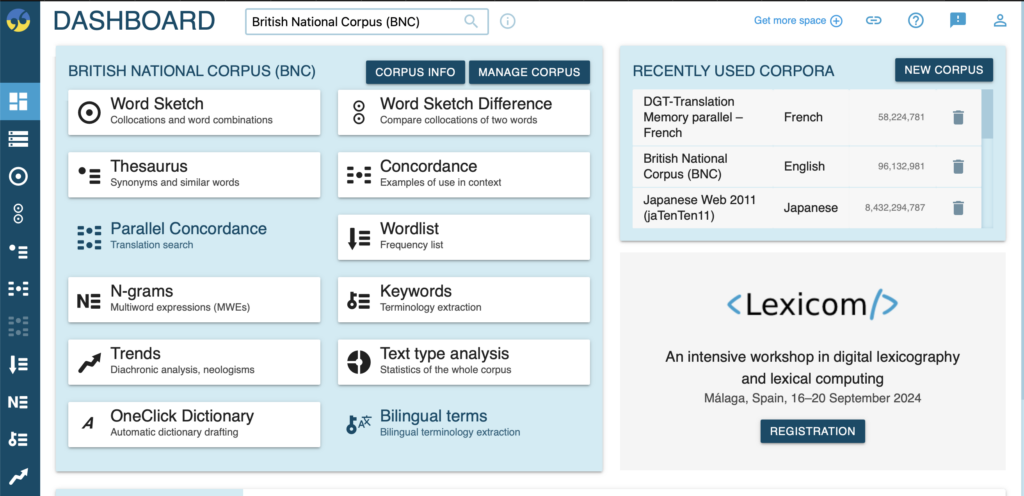
After successfully logging in you’ll be shown this home page, which conveniently lists out all of the available tools that sketch engine offers.While it may seem daunting at first each tool is relatively simple to make use of once we understand their functions. We’re going to quickly break them down and see what kind of information they contain.
Corpora & Concordance
One of the first tools we are shown is the concordance tool. Before diving into this we should take a brief look at the concept of a corpus, as corpora are the resources from which Sketch Engine collects all of its data.
In it’s most simple terms, a corpus is a collection of data that has already been marked up and is listed in concordance.
Marked up simply means that the data we are being shown has been previously organised using coding data, as language researchers who may have limited knowledge of coding scripts, this is a hugley beneficial feature. Part of the mark up in a corpus is that the sentences are delimited – i.e. the boundaries of the sentences are identified by this ‘mark up’ language.
I’ve linked a separate post from this website below which delves into the concept of corpora with more detail. I strongly recommend taking a look here to familiarise yourself with corpora before delving into Sketch Engine.
Now that we understand Corpora, let’s delve a bit deeper into the concordance tool.
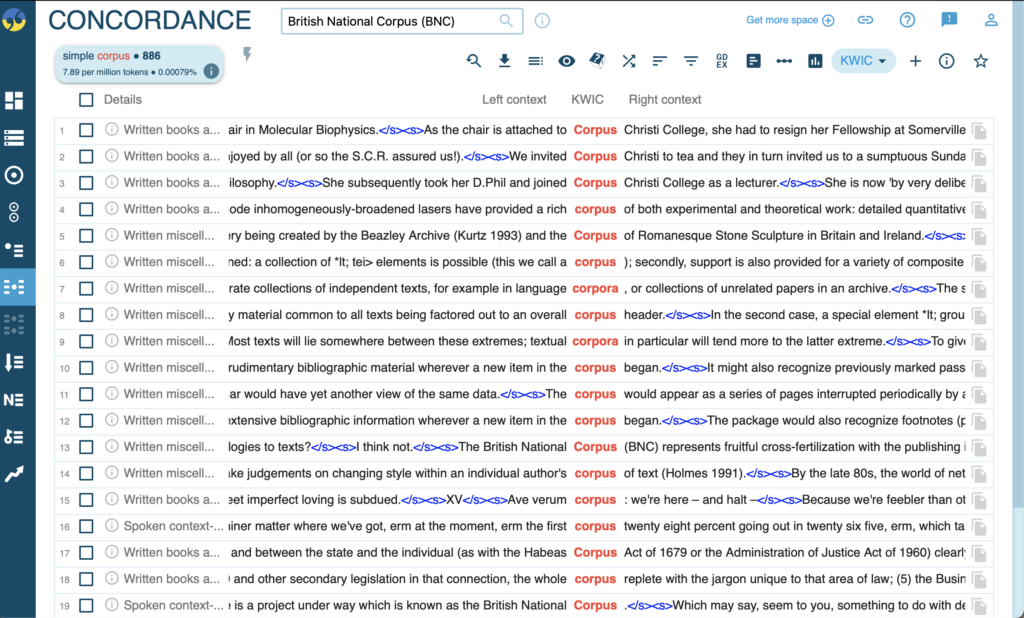
Think of concordance as equal to ‘context’, when viewing a corpus’ concordance, we are being shown the keyword or term we have searched with it’s left context and right context. While all of this may seem a little confusing at first, it’s useful to understand how Sketch Engine actually collects its data. The first course of action when looking to use any of the Sketch Engine tools is to choose a specific Corpus to work from. This could be anywhere from national corpora, a universities own corpus or any other corpus that Sketch Engine has been giving access to. All we have to do is select the search bar above and input our desired corpus, once this is done sketch engine now has access to all of its data and is ready to organise that data in whatever way we see fit depending on which tool we choose.
Here I have chosen the British National Corpus and searched the word ‘corpus’ as our chosen term. As we can see the keyword is highlighted in red in the centre with its left context and right context displayed on either side.
The sentences are delimited, with their boundaries identified by blue mark up language displaying <s/><s> to show the beginning and ending of each sentence. This tool is useful for understanding how and when to use a word. By viewing it in context we are given a much broader illustration of the word in practical use.
Word Sketch
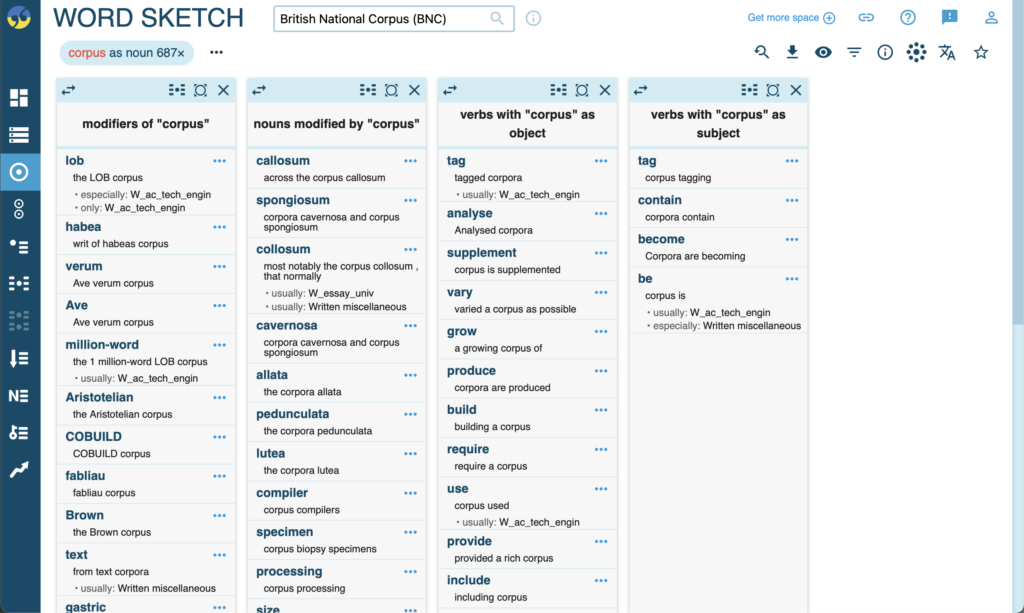
The first tool we see here is the word sketch. Think of the word sketch as a way of idenitfying the different uses of a word. If we search the word ‘corpus’ for example, the word sketch identifies this as a noun as shown in the top left corner, and lists the various collocations (or pairings) that are used most frequently within the corpus’ data. We have modifiers, objects, subjects, prepositions & so forth. The word sketch allows us to understand the nuance of the word while also shedding some light on how that word should be used in actual language.
There are some words that are idenitfied as multiple grammatical categories, for example the word ‘find’ can be used as both a noun and a verb. By selecting the category box in the upper left corner, we can move between these two categories and compare their collocations. Similarly, the word sketch difference tool allows us to search two terms at once and view their data side by side.
Word List
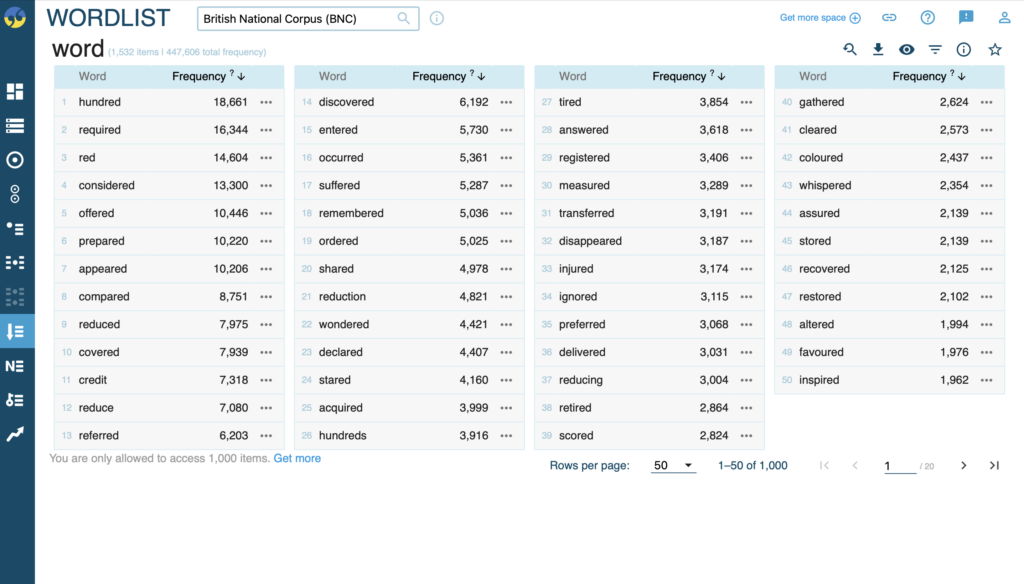
The word list tool simply shows the frequency of words within your chosen corpus. The data is displayed in list format from most frequent to least frequent.
This tool can be particularly useful for language research. Take translation for example. A researcher may choose a corpus based entirely off of data taken from specific translation to identifying any frequently used or marked choices translators of certain types of texts or translations choose to make.
It is also useful for learners of a second language to check the suitability of a certain word or phrase. They can identify commonly used words in their target language and note what words may be lacking in frequency or suitability in that language.
N – Grams
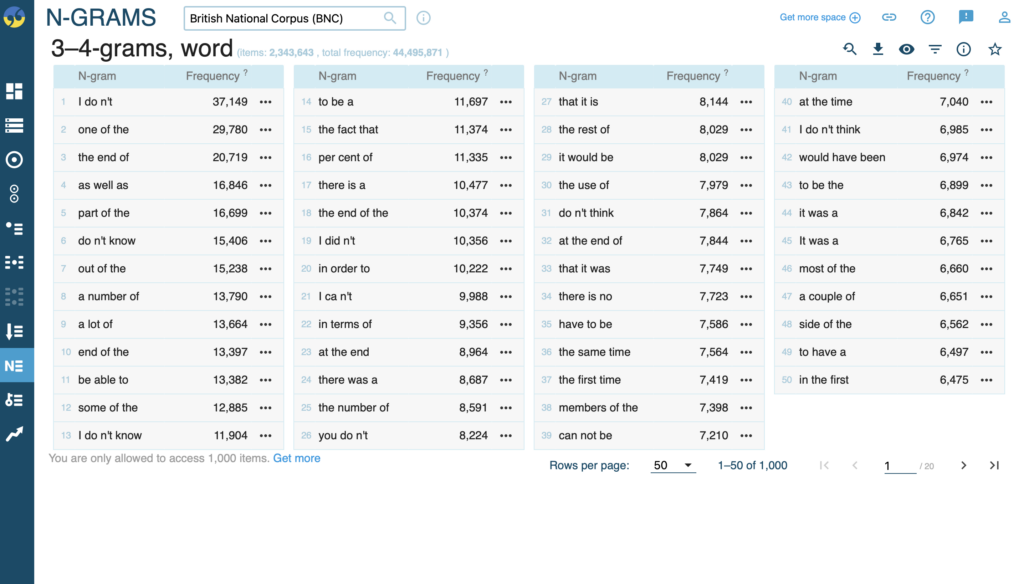
An n-gram is simply a continuous sequence of words, symbols or ‘tokens’. The n signifies the quantity of tokens searched for.
If we search up 3-4 grams in the British National Corpus, we are shown commonly used 3-4 grams within the data. They are listed here with the n-gram displayed on the left and it’s frequency displayed on the right. Once again the data is presented as most frequent to least frequent. This tool can be especially useful for linguistic research or for those with a focus on grammar and word choice/function.
Thesaurus
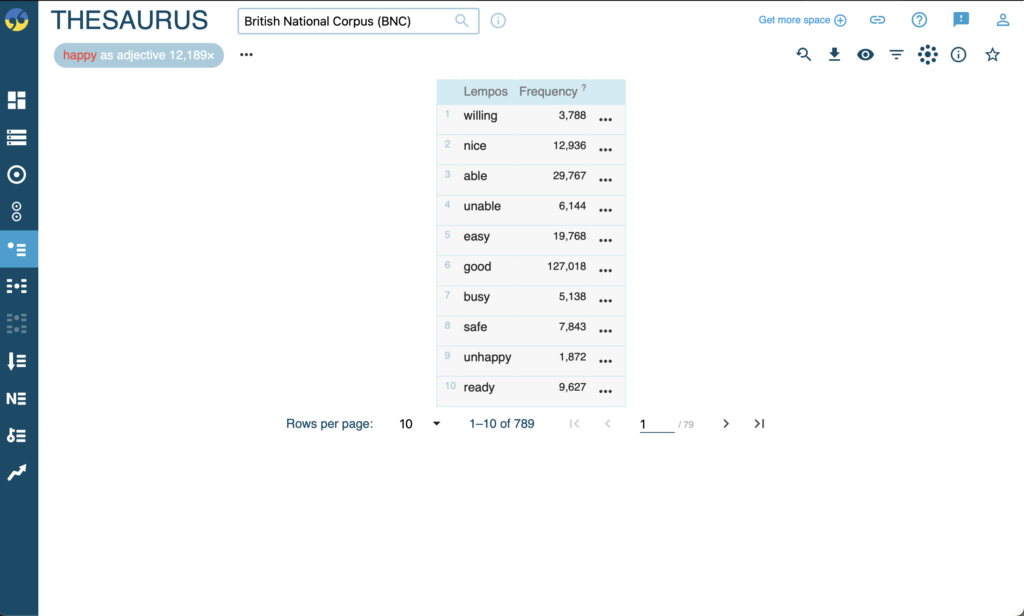
Finally we have the Thesaurus tool. This may be the tool a user would be the most familiar with upon their first experience with Sketch Engine. You simply searched your desired word and synonyms found within that corpus are listed out alongside their frequency.
This functions in the same way that a traditional thesaurus would and it’s an overall useful tool for language study.
In conclusion
Sketch Engine is an extremely useful tool for both language research and language learning. While it’s wide array of tools may seem daunting at first, once you familiarise yourself with the content, how to use it and what the data means it becomes an invaluable asset to a language student.
Leave a Reply