

Today we are going to explore the world of corpora.
What is a corpus, how do we use it and what insights can it offer into linguistic studies? Let’s find out.
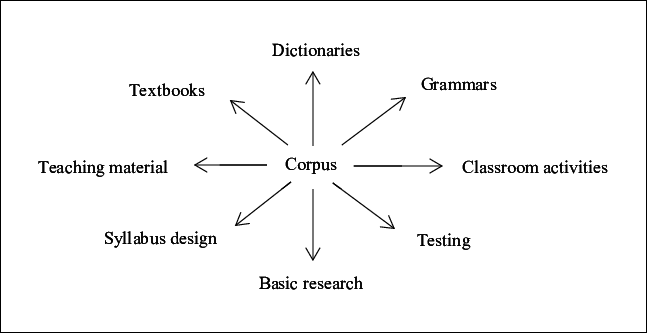
What is a corpus & how do we use it?
So what exactly is a corpus?
In its most simple of terms, a corpora is a collection of data on specific words or phrases that allows us as linguists to analyse the function, frequency and characteristics of a given word.
A corpus achieves this by presenting its collected data in a clear, systematic manner. One of the key features to keep in mind when using corpora is that the data is displayed in concordance.
Concordance simply means that the data is organised and presented around a keyword and its context, the keyword being the chosen term or word and the context being the words surrounding it and any other grammatical features often associated or used alongside the keyword. This idea of concordance is often referred to as KWIC (keyword in context).
A typical corpus presents the keyword within the centre with a left context and a right context on each side. The corpus searches its catalogue for occurrences of the keyword and will show us in list form all of these occurrences alongside their context.
Another key feature is that the collection of data shown is already marked up, the sentences are delimited, features such as sentence boundaries are pre-identified with coding information on the data already present.
The below screenshot of the British National Corpus (accessed using sketch engine) shows all of these features in use.
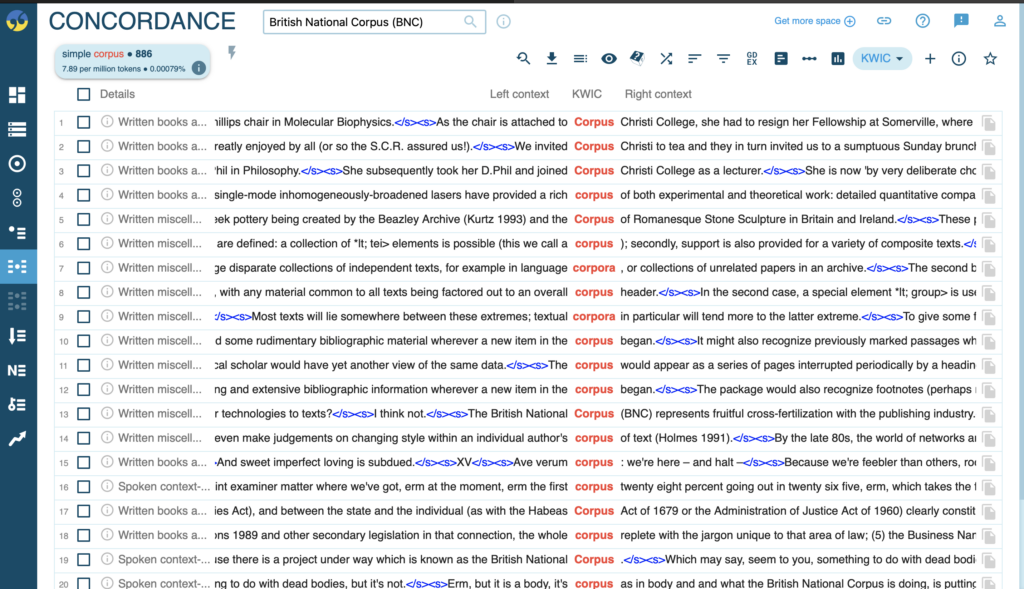
Here we can see the data presented in list form with the searched term (in this case I used the word ‘corpus’) in the centre with its’ left and right context. The markings in blue are coding information identifying the beginning and ending of each sentence within the context.
Corpora in Linguistic Studies
Now that we have a basic understanding of how to use a corpus, let’s explore the possibilities they hold for language studies.
Aside from the obvious uses of grammatical linguistics, corpora are also an invaluable tool for second language learners. By displaying the data in concordance, we gain a broader understanding of the usage and sense of a word. The nuanced and ever-evolving nature of language can render basic vocabulary lists redundant in many cases. Even if you aren’t a seasoned academic or researcher, the clarity that a corpus can provide to the second language learner is invaluable. Language will always operate within a specific social, cultural and geographical context, the ability to access and use corpora extends the opportunity to understand this context.
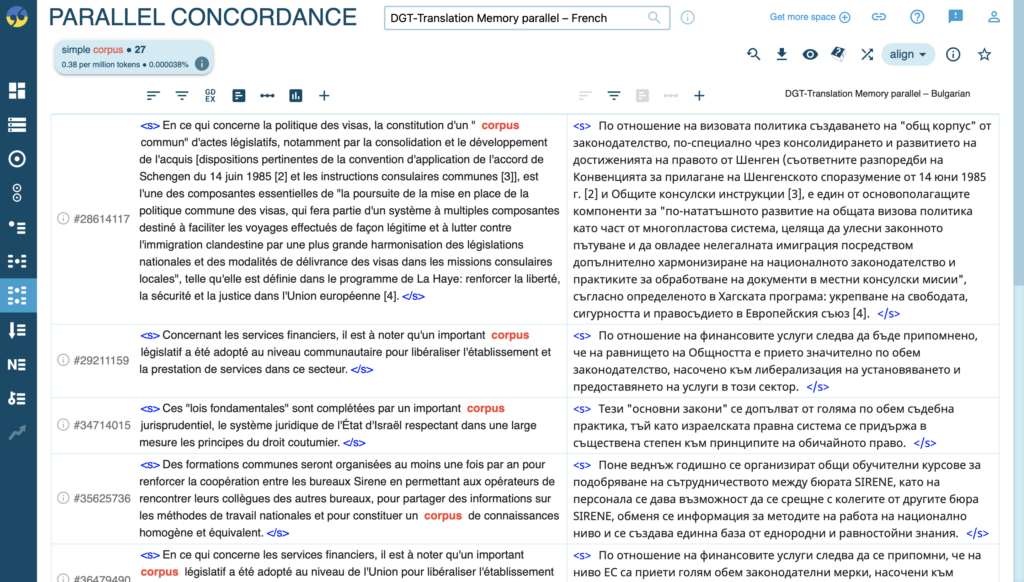
Corpora also provide an immense amount of help in translation between languages. A translator of a medical journal for example can make use of a parallel corpus (wherein a term is searched and data is displayed from more than one corpus) to understand the frequency (or lack of) of a medical term in their target language and take this into consideration when translating their text.
Alternatively, a researcher of translations studies could select a corpus compiled specifically of data taken from translations and use this to understand marked or characteristic word choices translators of specific languages choose to use.
The below screen shot shows the parallel concordance between a French and Bulgarian corpus.
In conclusion
Hopefully this post offered a bit of clarity on the daunting idea of a corpus and how to access one to its fullest potential. The world of corpora is closely connected to word nets, n-grams and even basic word lists, topics that will all be explored in our next post.
If there is any unclarity or lingering questions you find yourself left with, I’ve linked a helpful video underneath from the Phloneme channel which breaks the concept of a corpus down in an easy and accessible manner.
All the best.
Leave a Reply